We introduce MeshGPT, a new approach for generating triangle meshes that reflects the compactness typical of artist-created meshes, in contrast to dense triangle meshes extracted by iso-surfacing methods from neural fields. Inspired by recent advances in powerful large language models, we adopt a sequence-based approach to autoregressively generate triangle meshes as sequences of triangles.
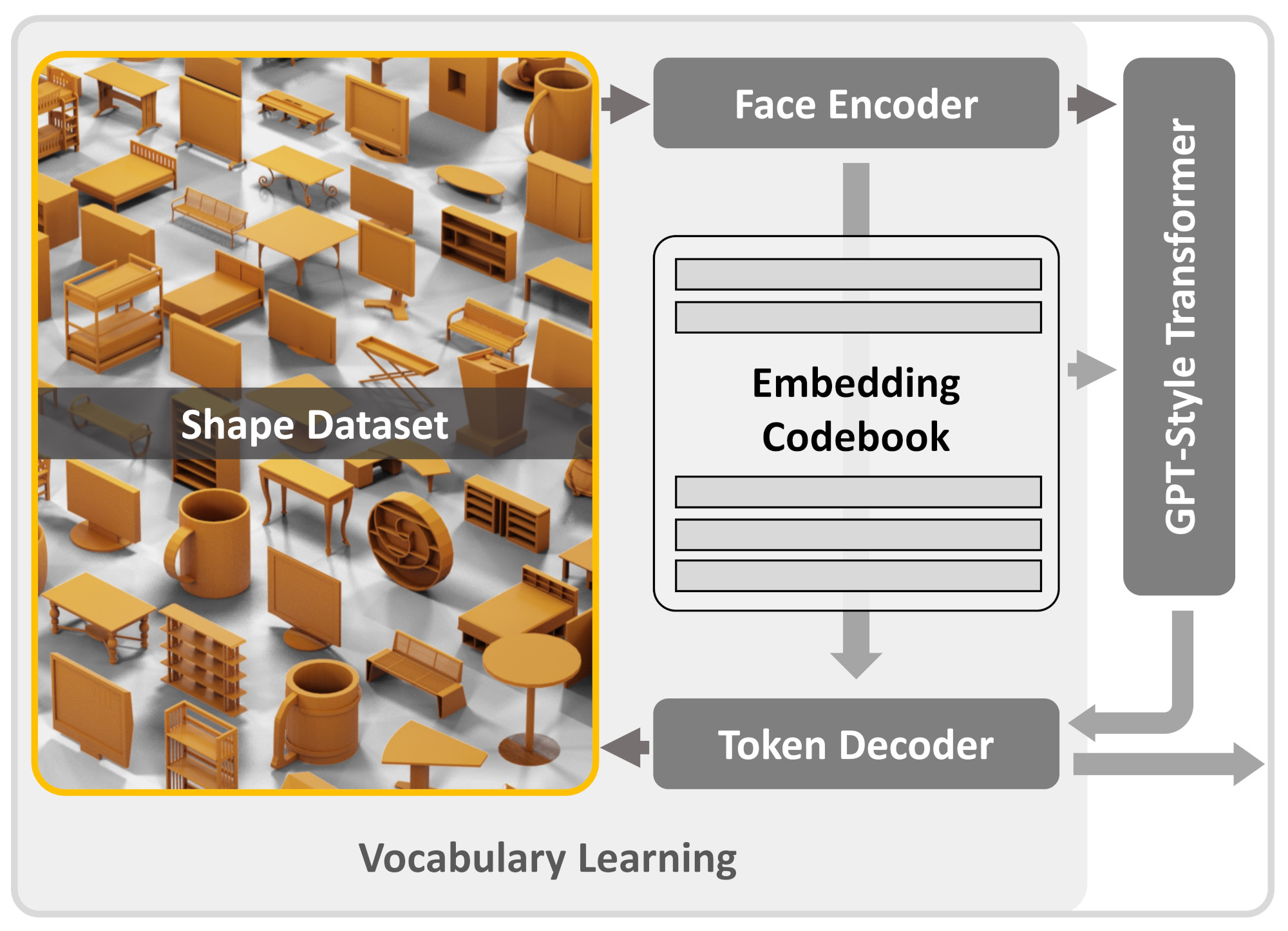
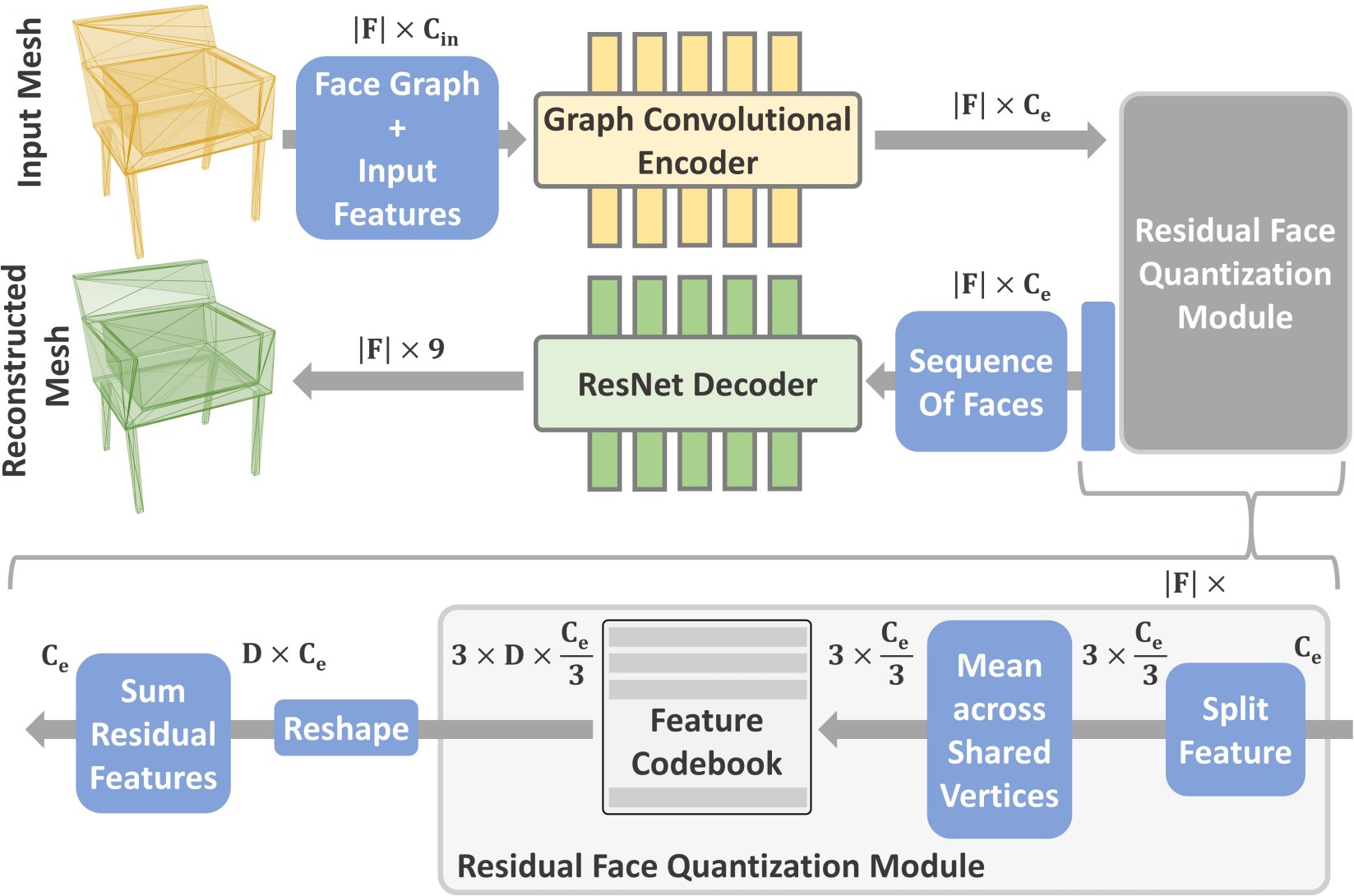
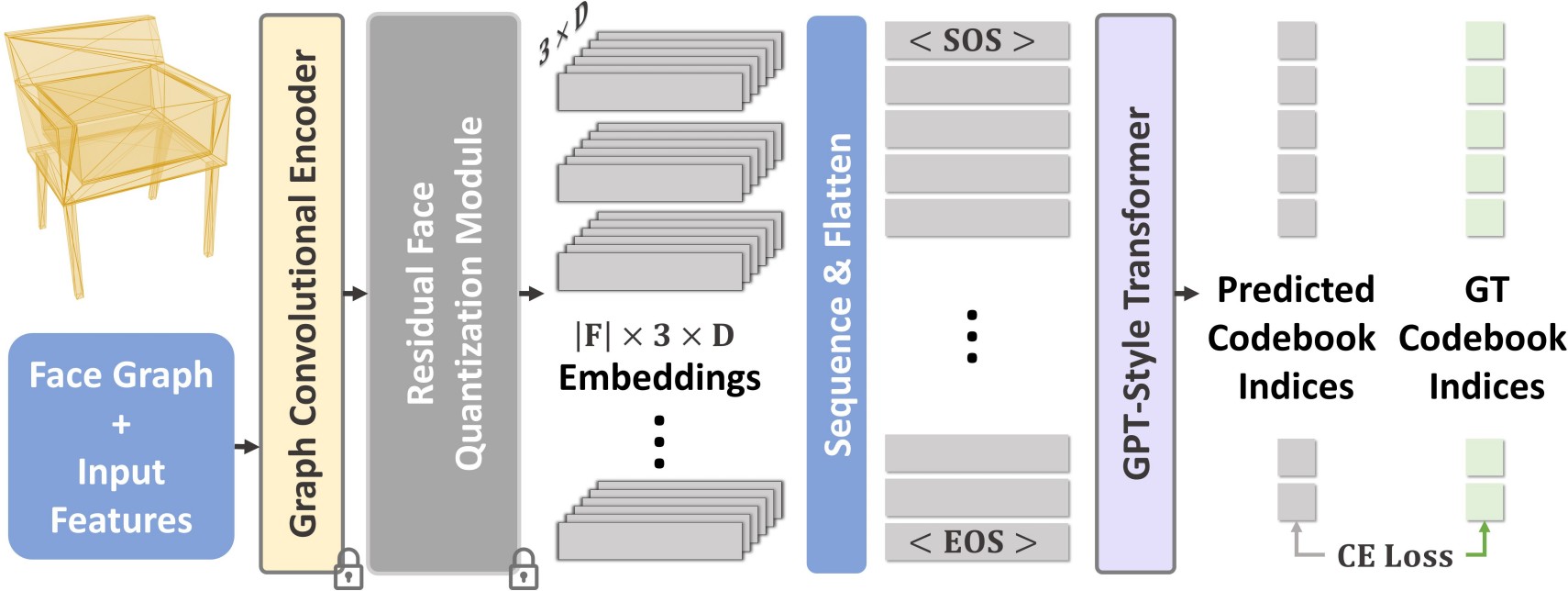
We first learn a vocabulary of latent quantized embeddings, using graph convolutions, which inform these embeddings of the local mesh geometry and topology. These embeddings are sequenced and decoded into triangles by a decoder, ensuring that they can effectively reconstruct the mesh. A transformer is then trained on this learned vocabulary to predict the index of the next embedding given previous embeddings. Once trained, our model can be autoregressively sampled to generate new triangle meshes, directly generating compact meshes with sharp edges, more closely imitating the efficient triangulation patterns of human-crafted meshes.
MeshGPT demonstrates a notable improvement over state of the art mesh generation methods, with a 9% increase in shape coverage and a 30-point enhancement in FID scores across various categories.
Our approach produces compact meshes with sharp geometric details. In contrast, baselines often either miss these details, produce over-triangulated meshes, or output too simplistic shapes.
Given a partial mesh, our method can infer multiple possible shape completions.
Here we show completion as the partial input mesh is edited through user actions.
Our method can be used to generate 3D assets for scenes. Here we show a room populated with assets generated using our method.
Vocabulary Learning
Transformer Training
We first learn a vocabulary for triangle meshes, which we then use for autoregressive generation of a mesh.We learn our vocabulary of geometric embeddings from a vast collection of shapes. This is done using an encoder-decoder network, which features vector quantization at its bottleneck.
This transformer is specifically designed for sequence prediction over tokens from the learned vocabulary.
Once fully trained, it enables the direct sampling of meshes as sequences from this vocabulary.
For more work on similar tasks, please check out
PolyGen: An Autoregressive Generative Model of 3D Meshes generates meshes with two transformers, one for generating points, and another with faces with the help of pointer networks.
BSP-Net, a network that generates compact meshes via binary space partitioning.
AtlasNet: A Papier-Mâché Approach to Learning 3D Surface Generation represents a 3D shape as a collection of parametric surface elements.
Mesh Diffusion uses a 3D diffusion model to generate 3D meshes parametrized by deformable marching tetrahedra (DMTets).
@article{siddiqui2023meshgpt,
title={MeshGPT: Generating Triangle Meshes with Decoder-Only Transformers},
author={Siddiqui, Yawar and Alliegro, Antonio and Artemov, Alexey and Tommasi, Tatiana and Sirigatti, Daniele and Rosov, Vladislav and Dai, Angela and Nie{\ss}ner, Matthias},
journal={arXiv preprint arXiv:2311.15475},
year={2023}
}