RetrievalFuse
Neural 3D Scene Reconstruction with a Database
1Technical University of Munich 2Apple
Video
Abstract
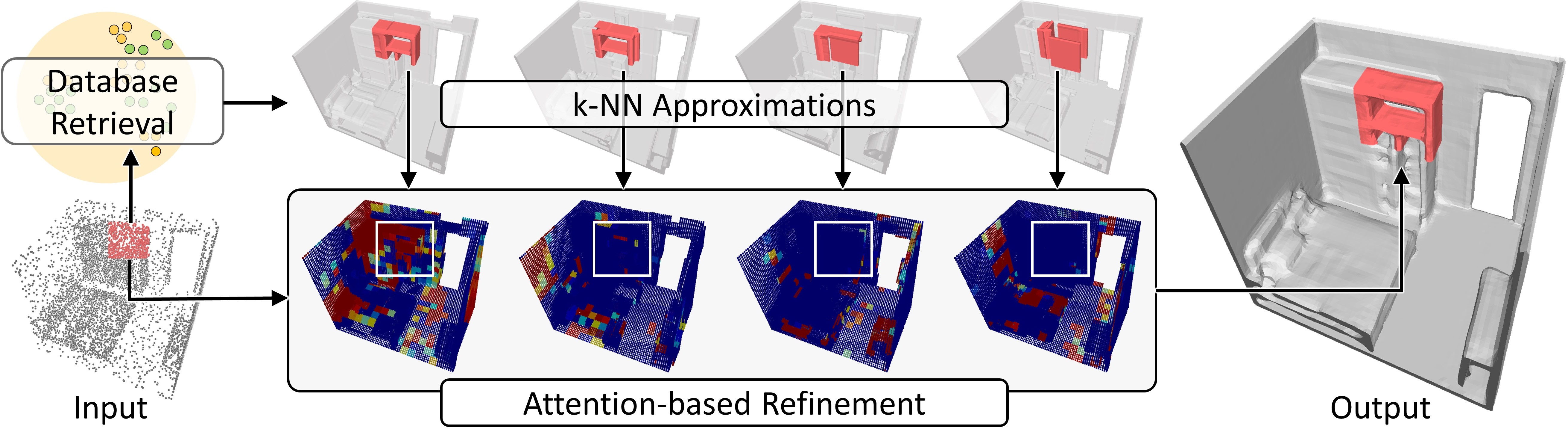
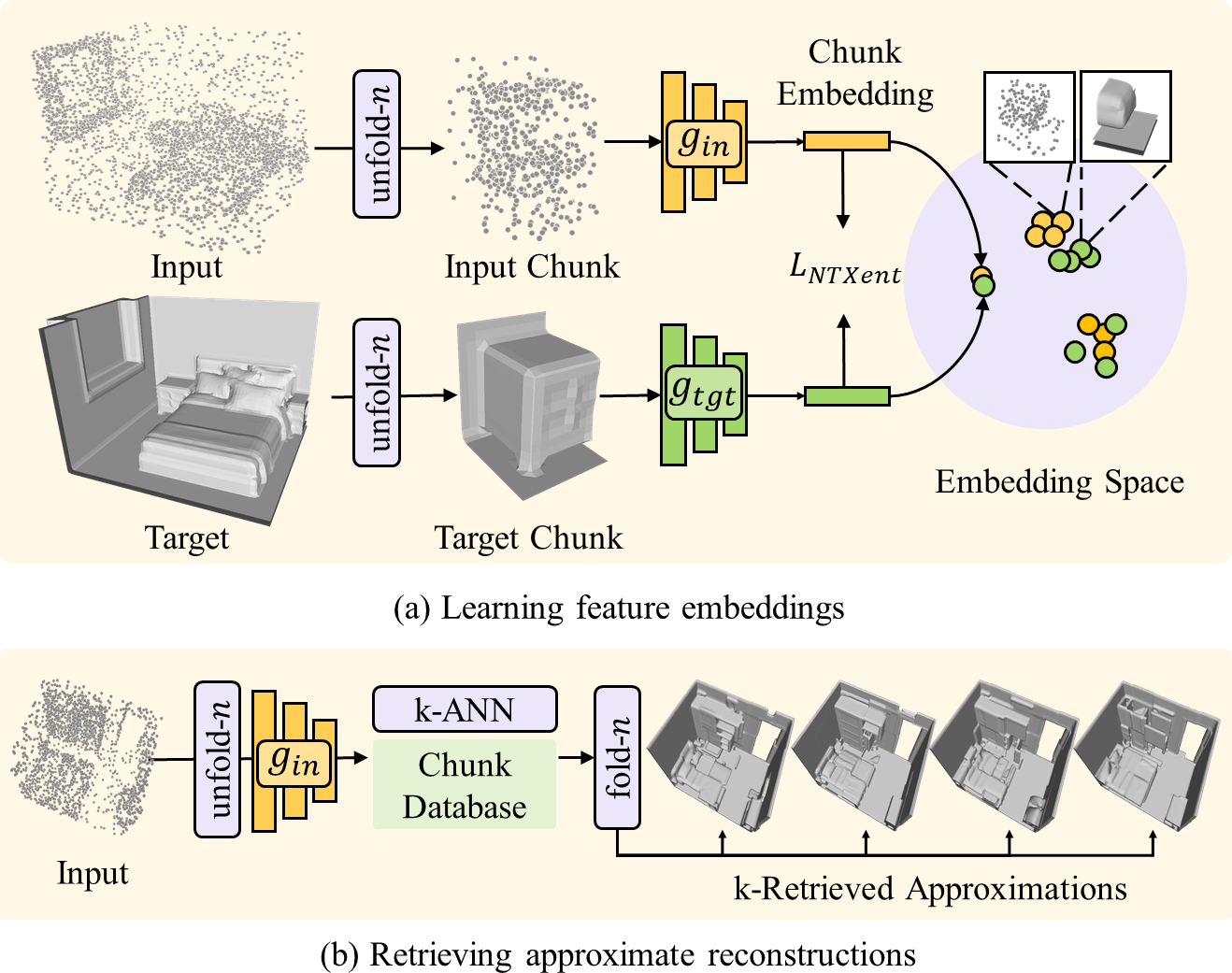
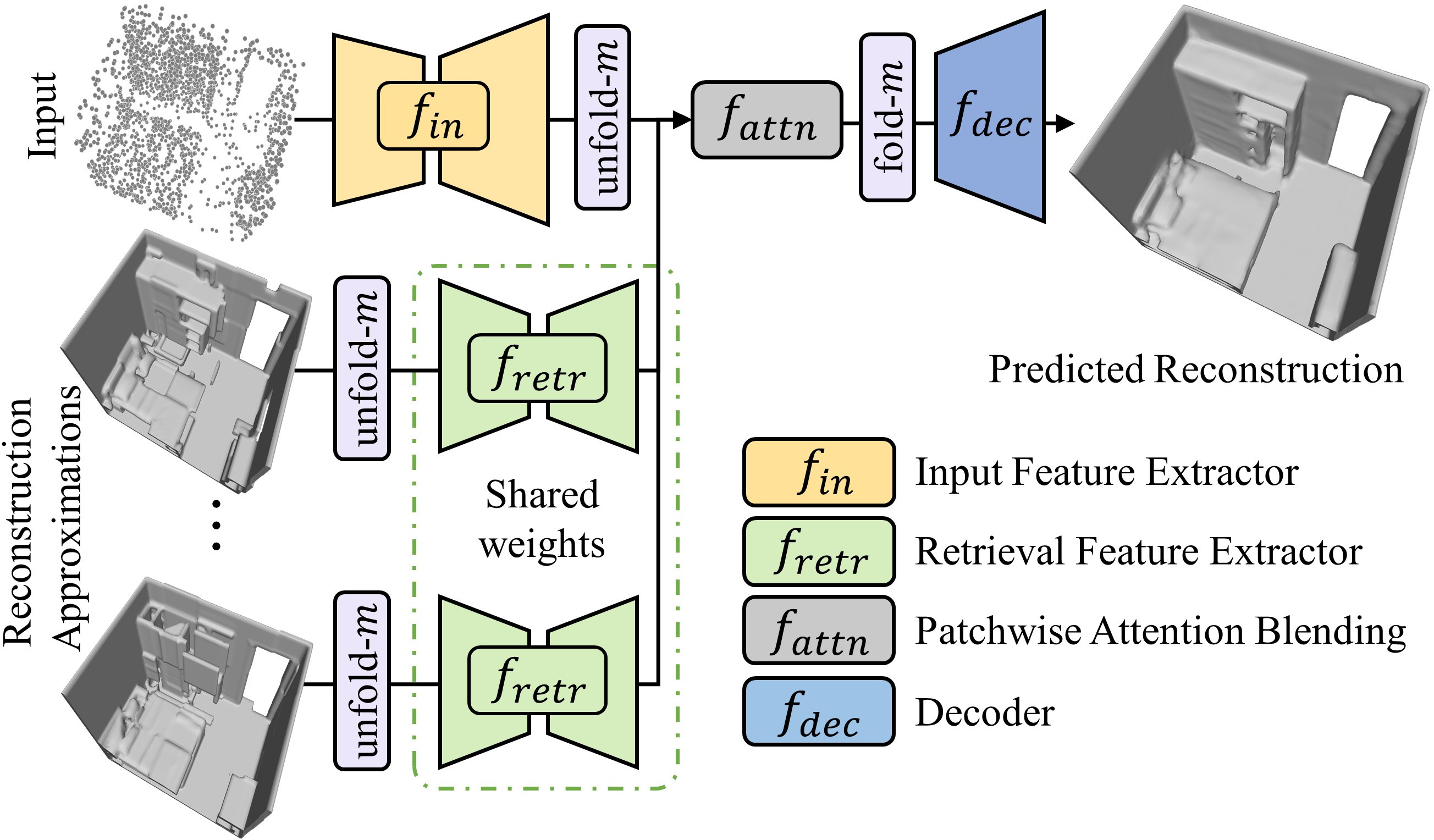
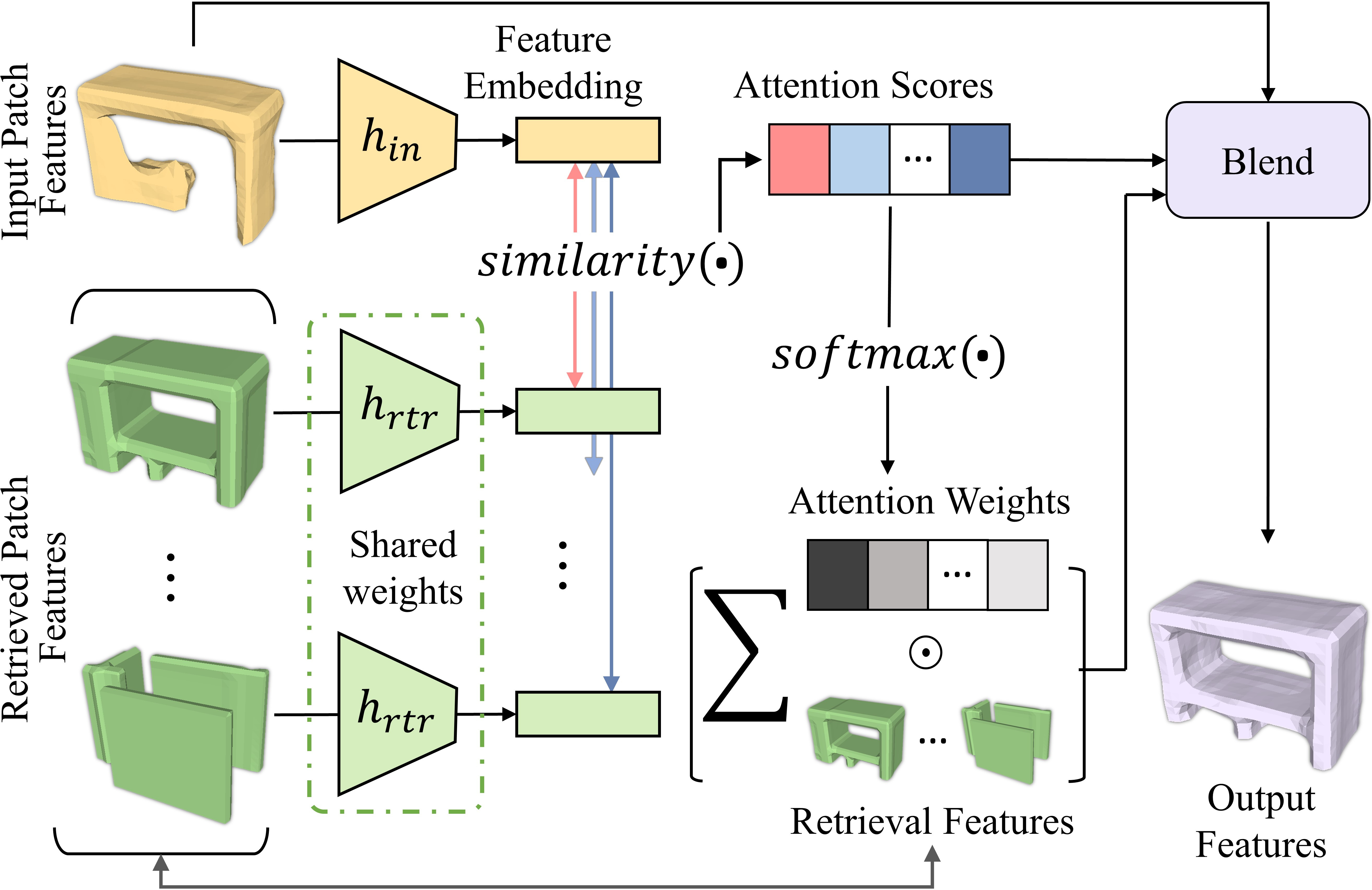
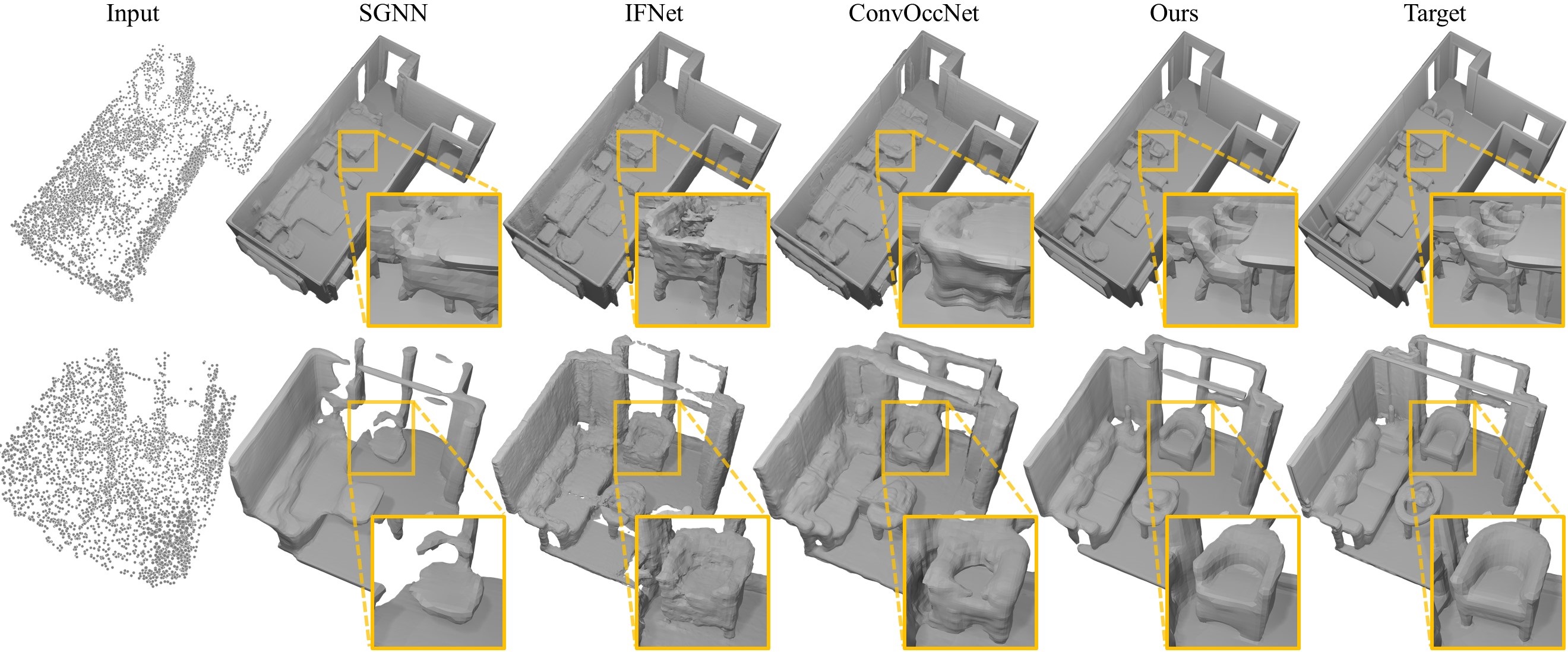
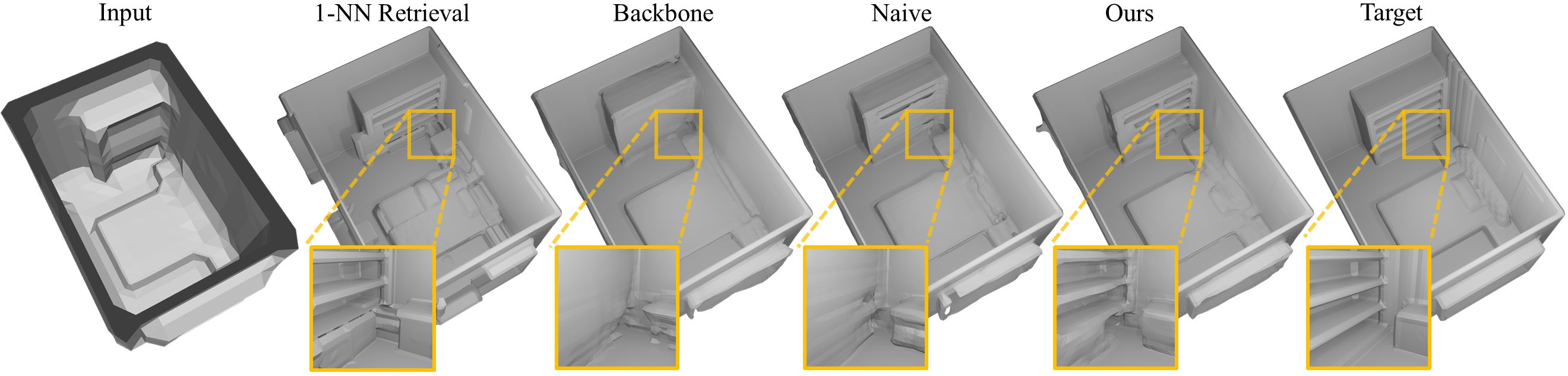
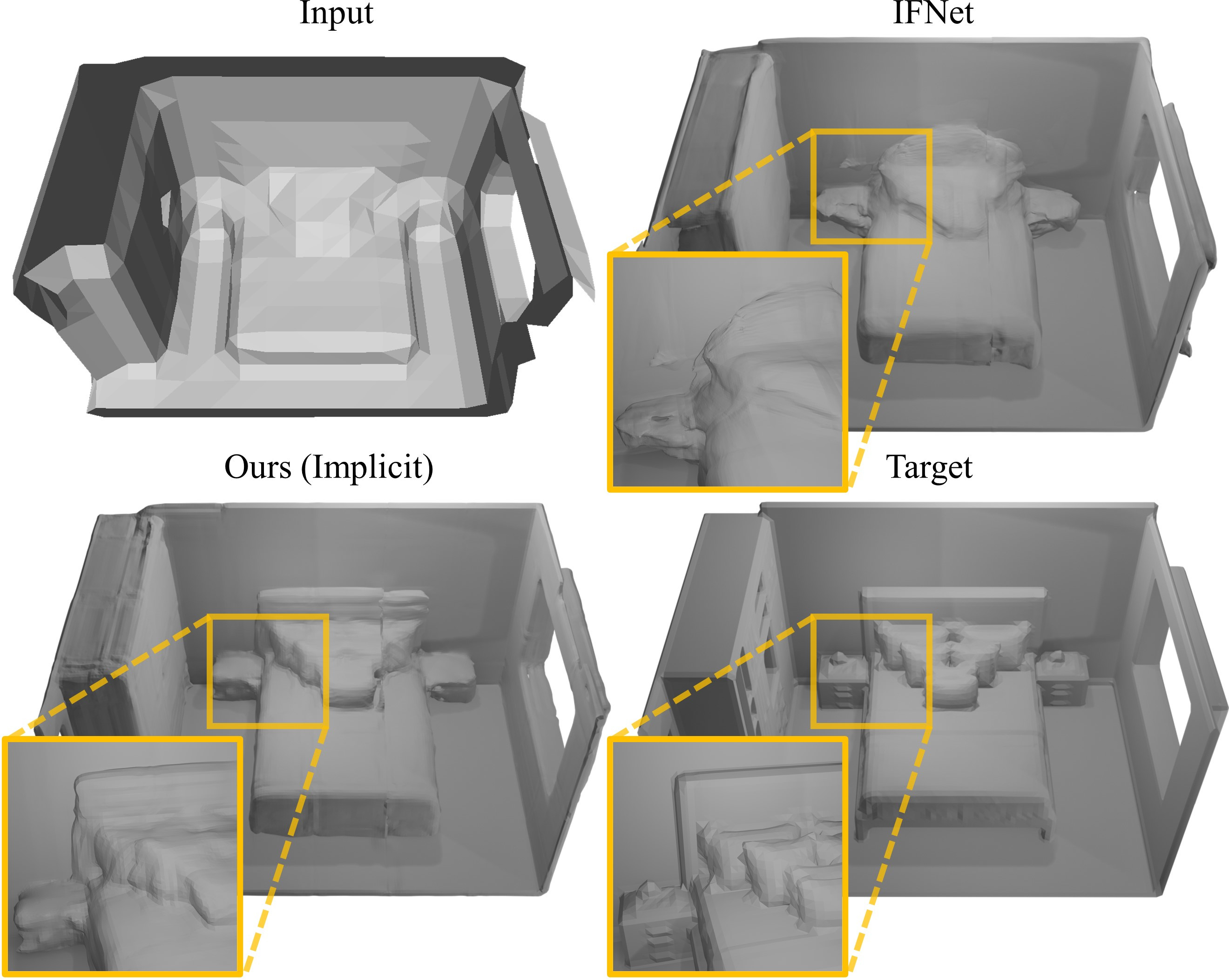
3D reconstruction of large scenes is a challenging problem due to the high-complexity nature of the solution space, in particular for generative neural networks. In contrast to traditional generative learned models which encode the full generative process into a neural network and can struggle with maintaining local details at the scene level, we introduce a new method that directly leverages scene geometry from the training database. First, we learn to synthesize an initial estimate for a 3D scene, constructed by retrieving a top-k set of volumetric chunks from the scene database. These candidates are then refined to a final scene generation with an attention-based refinement that can effectively select the most consistent set of geometry from the candidates and combine them together to create an output scene, facilitating transfer of coherent structures and local detail from train scene geometry. We demonstrate our neural scene reconstruction with a database for the tasks of 3D super resolution and surface reconstruction from sparse point clouds, showing that our approach enables generation of more coherent, accurate 3D scenes, improving on average by over 8% in IoU over state-of-the-art scene reconstruction.
Figures
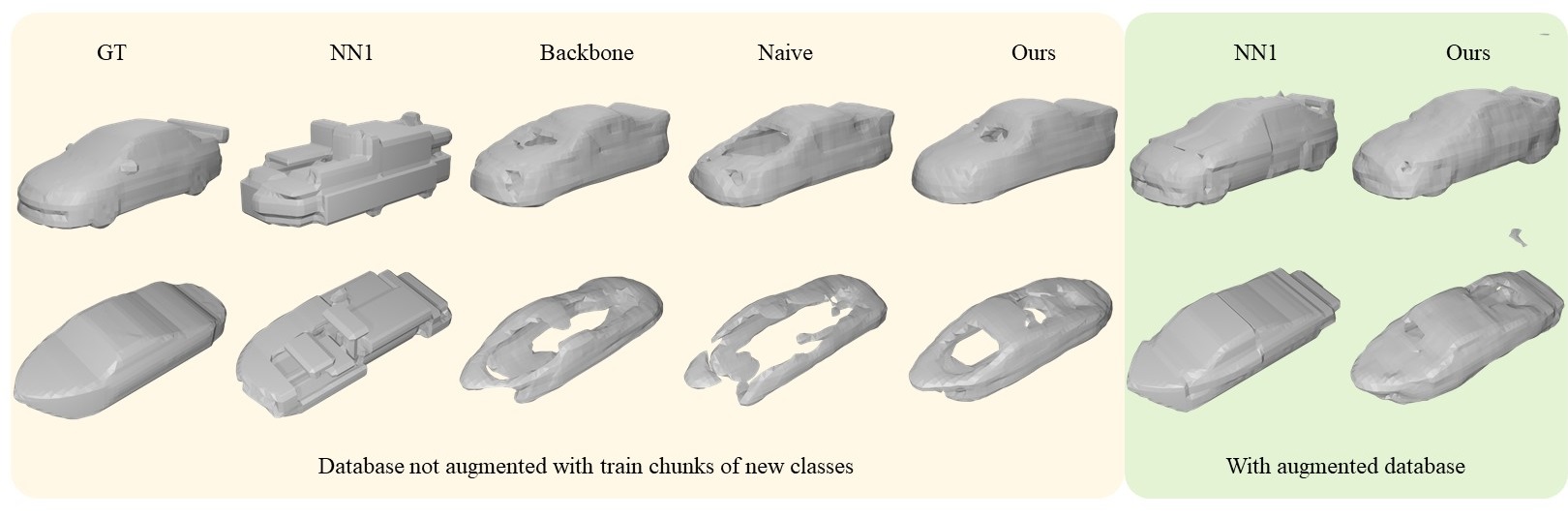
Click to enlarge and view caption.

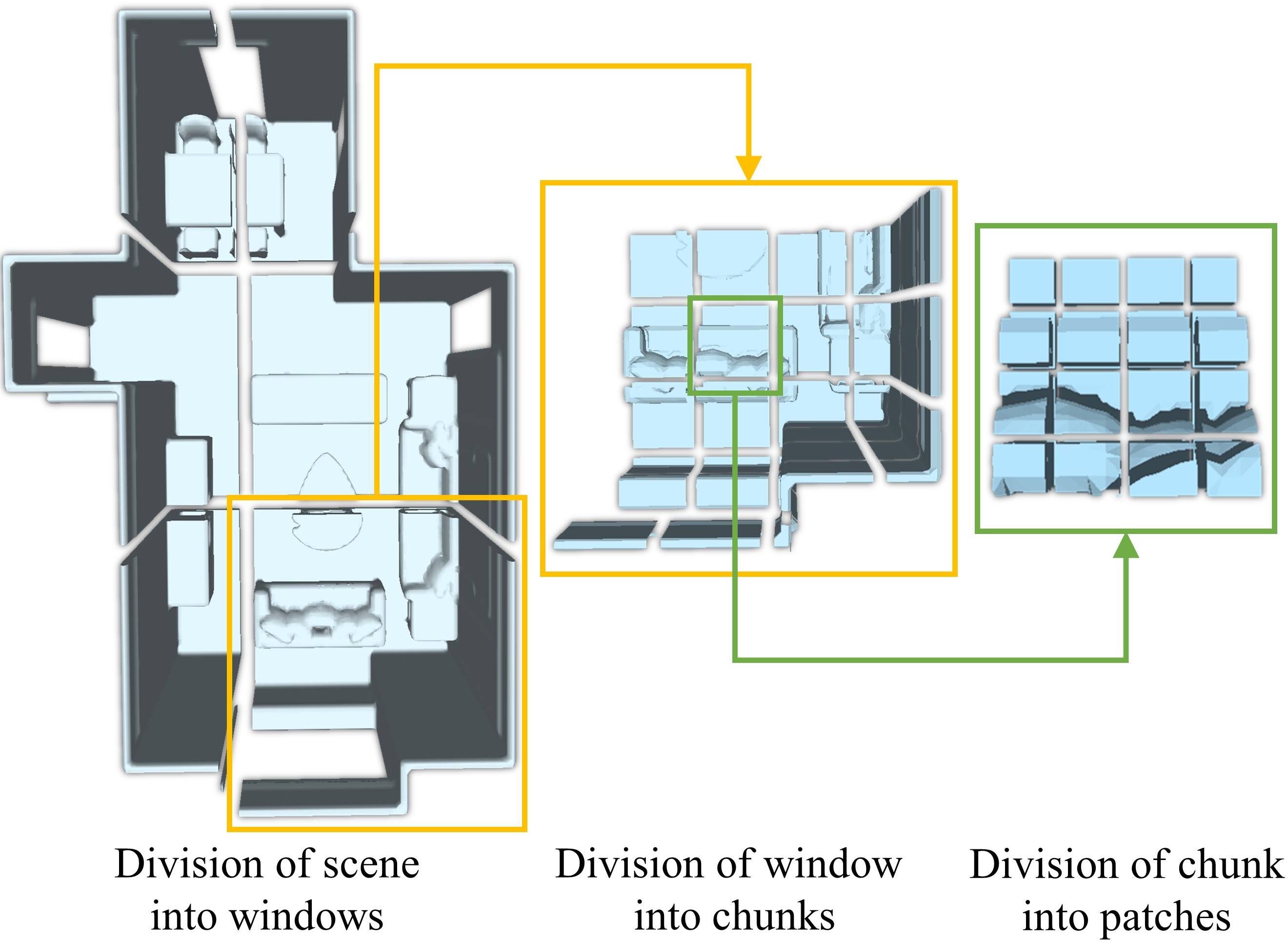
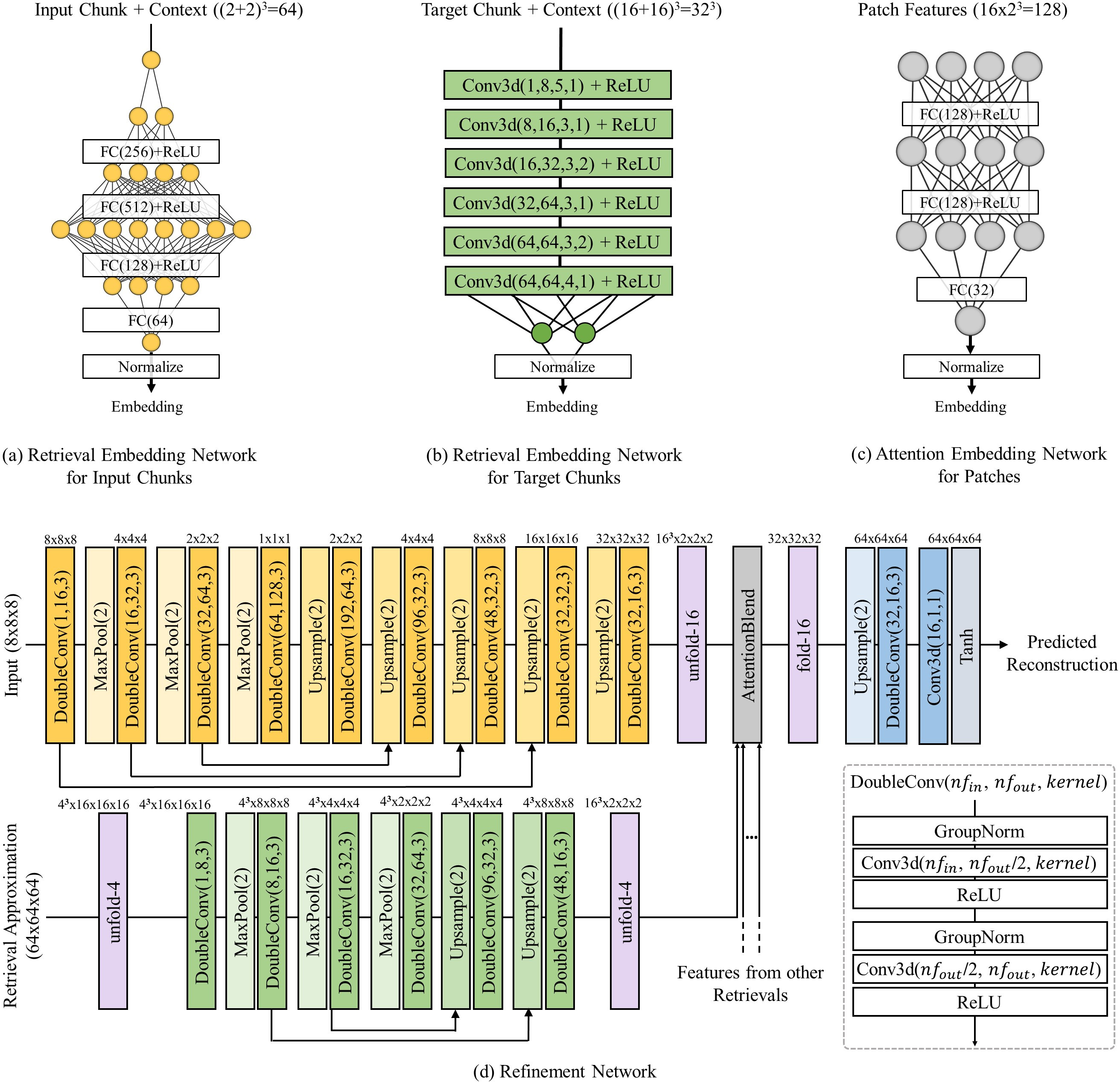
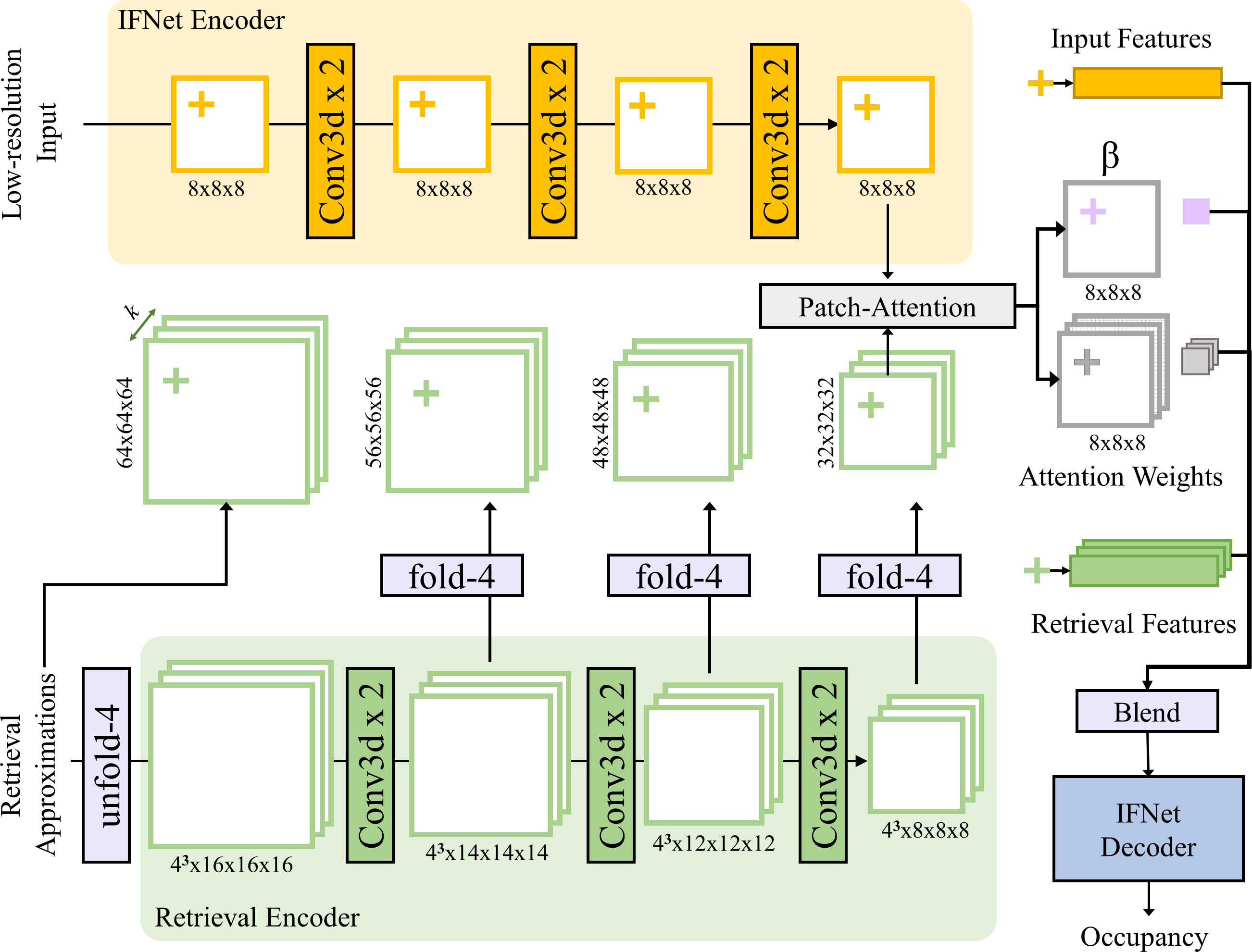
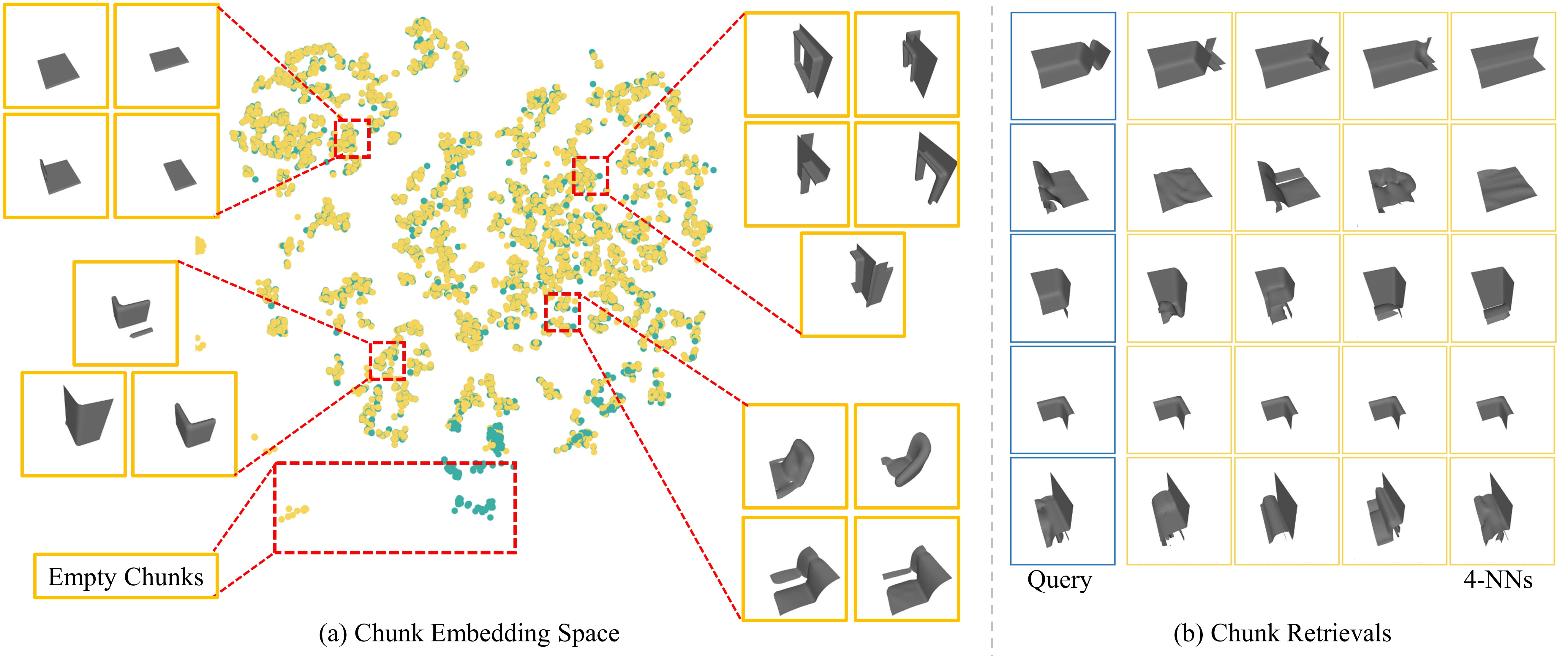





Publication
 If you find our project useful, please consider citing us:
If you find our project useful, please consider citing us:
@article{siddiqui2021retrievalfuse,
title = "{RetrievalFuse: Neural 3D Scene Reconstruction with a Database}",
author = {{Siddiqui}, Yawar and {Thies}, Justus and {Ma}, Fangchang and {Shan}, Qi and {Nie{\ss}ner}, Matthias and {Dai}, Angela},
journal = {arXiv e-prints},
keywords = {Computer Science - Computer Vision and Pattern Recognition},
year = 2021,
month = mar,
eid = {arXiv:2104.00024},
pages = {arXiv:2104.00024},
archivePrefix = {arXiv},
eprint = {2104.00024},
primaryClass = {cs.CV},
}